Künstliche Intelligenz gilt als das große „Buzzword“ unserer Tage. Insbesondere im Marketing wird der Technologie ein enormes Potenzial zugeschrieben. Dabei besteht eigentlich bis heute kein Konsens darüber, was nun genau unter „KI“ zu verstehen ist, eine einheitliche Definition existiert nicht. Allerdings gibt es hierbei so etwas wie einen „gemeinsamen Nenner“, einen Aspekt, bei dem sich alle einig darüber sind, dass es sich hierbei um etwas „künstlich Intelligentes“ handeln muss, nämlich dann, wenn wir von der Lernfähigkeit eines Systems sprechen. Für den zielgerichteten Einsatz von KI im Marketing spielt die Art der verwendeten Lernmethoden eine große Rolle.
KI im Marketing
Die Fähigkeit zu Lernen haben wir bisher immer mit Intelligenz verknüpft, nur intelligenten Lebewesen billigen wir diese Kompetenz zu: Ein Mensch erweitert im wörtlichen Sinne seinen Horizont, indem er lernt und neue Kenntnisse und Fertigkeiten erwirbt. Ein Hund kann lernen, zu apportieren oder auf bestimmte Befehle trainiert werden. Aber auch ohne menschliche Anleitungen baut er sich eigenständig einen Erfahrungsschatz auf, auf den er bei der Beurteilung von Situationen zurückgreifen kann, um sich in ähnlichen Situationen ähnlich zu verhalten – und zwar jenseits von angeborenen Instinkten. Das unterscheidet ihn von anderen, weniger oder nicht „intelligenten“ Tieren. Will man Intelligenz künstlich reproduzieren, so scheint dies zwangsläufig dazu zu führen, dass dabei insbesondere auch das permanente Ansammeln von Wissen und Erfahrungen, die fortwährende Erkennung von Wirkungszusammenhängen sowie die Ableitung und Aufbereitung von Erkenntnissen daraus ein wesentlicher Bestandteil sein muss – letztlich handelt es sich hierbei ebenso um typische Anforderungen, die auch für das Marketing gelten.
Maschinelles Lernen: eigenständige „Erkenntniszuwächse“ eines Systems
Mit „maschinellem Lernen“ (engl. Machine Learning) wird in der Regel die Fähigkeit eines Systems verbunden, automatisch zu lernen, ohne dabei fest auf die Ergebnisausgabe „programmiert“ zu sein – also ohne hierzu auf ein menschlich vorgegebenes, statisches Regelwerk zurückzugreifen oder einzelne Elemente einfach auswendig zu lernen. Vielmehr geht es darum, Erkenntniszuwächse eigenständig aus der Identifizierung von Mustern zu erzielen und bestimmte Gesetzmäßigkeiten aus bereitgestellten Datensätzen abzuleiten. Damit wird das System in die Lage versetzt, auch Vorhersagen über bestimmte Muster zu treffen, indem auf Basis der erkannten logischen Zusammenhänge Algorithmen modelliert werden, die dann automatisiert typische Datenprofile ermitteln und/oder Anomalien in der Datenstruktur aufdecken.
Unterschieden wird meist in drei Ansätze,
• dem überwachten Lernen (engl. Supervised Learning)
• dem verstärkenden Lernen (engl. Reinforcement Learning), und
• dem unüberwachten Lernen (engl. Unsupervised Learning)
wobei diese nicht nur unterschiedliche Verfahren darstellen, sondern auch grundsätzlich unterschiedliche Ziele haben.
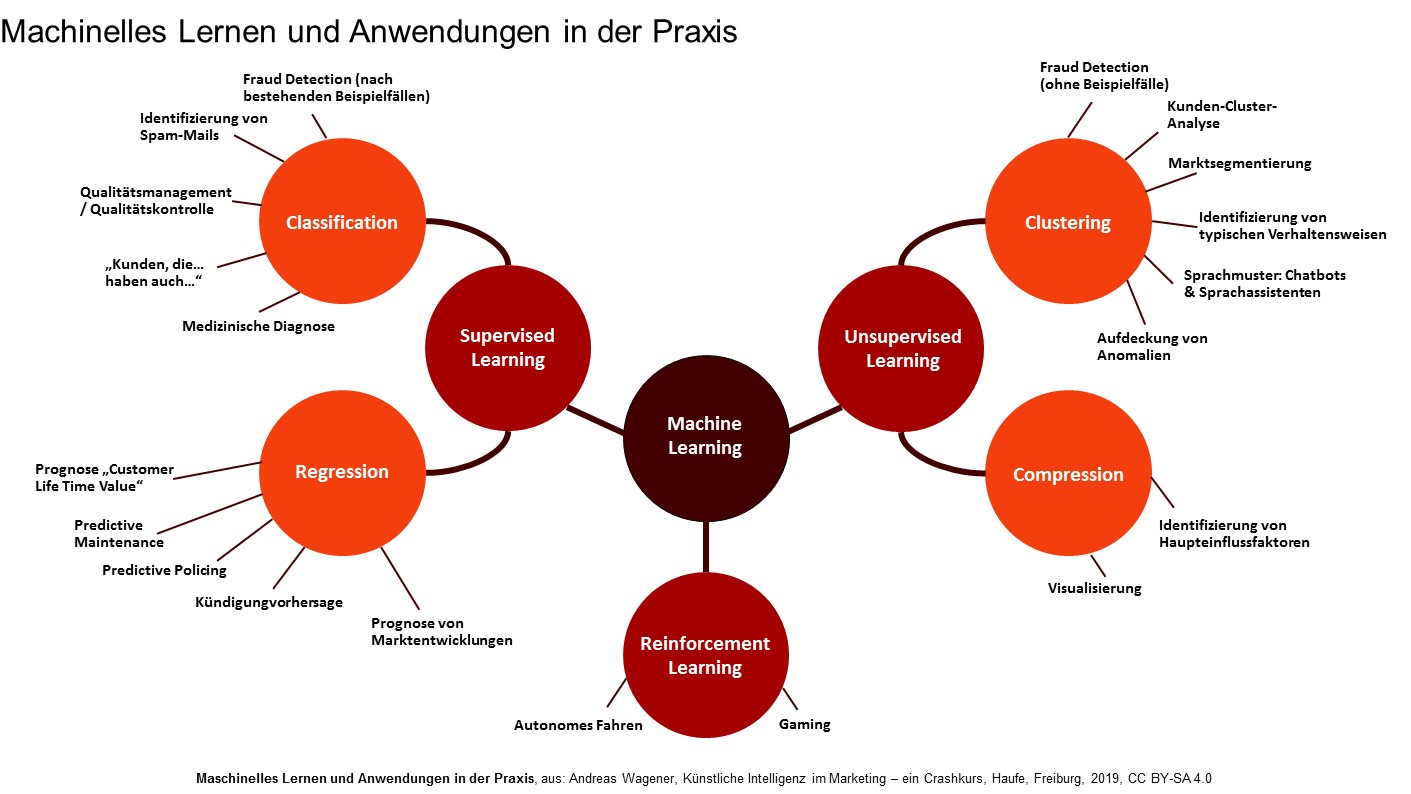
Überwachtes Lernen: Anleitung des Systems
Von überwachtem Lernen spricht man, wenn das Ergebnis – die „Erkenntnis“ – bereits vorliegt und lediglich der Weg dorthin „trainiert“ werden soll. Dies geschieht anhand von schon existierenden Input-Output-Paaren: es liegen also ein Input-Signal und ein entsprechendes Output-Signal vor, beide haben einen kausalen Zusammenhang, d.h. das Input-Signal, eine bestimmte Ausgangslage, führt zwangsläufig zu einem bestimmten Output, also einem vorhersagbaren Ergebnis. Es geht somit darum, bekannte Gesetzmäßigkeiten nach- bzw. abzubilden, oft in Form von sogenannten „Entscheidungsbäumen“ („wenn…, dann …“). Die Ergebnisse des Lernprozesses lassen sich mit den bekannten, richtigen Ergebnissen vergleichen, also „überwachen“.
Regression und Klassifikation: quantitative und qualitative Mustererkennung
Grundsätzlich unterscheidet man zwischen Regressions- und Klassifikationsproblemen. Letztere beziehen sich auf die „Einsortierung“ einer qualitativen Erkenntnis, wie dies etwa bei der Identifizierung von Spam-Mails Anwendung findet. Das System wird hierbei mit „echten“ Spam-Mails trainiert, anhand der dabei als spezifisch erkannten Eigenschaften kann es später eigenständig entscheiden, ob eine Nachricht als Spam zu klassifizieren ist oder nicht. In der Praxis übernehmen dann häufig die Nutzer der eMail-Programme den Feinschliff: Jedes Mal, wenn wir eine Nachricht als „Spam“ markieren, lernt das System hinzu und bezieht diese neuen Erkenntnisse bei späteren Entscheidungen mit ein. „Regression“ bezieht sich stattdessen auf quantitative Ergebnisse. Hier geht es also um die Bestimmung eines Zahlenwertes, etwa zur Prognose von Preisentwicklungen oder zur Festlegung bestimmter Eintrittswahrscheinlichkeiten – wie zum Beispiel der Voraussage von Kündigungszeitpunkten oder des „Customer Life Time Values“ (des Kundenwertes). Auch dies geschieht auf der Basis „antrainierter Erkenntnisse“ von Musterzusammenhängen.
Re-Inforcement Learning – eigenständiges „Verstärkungslernen“
Das Verfahren des „Reinforcement Learning“ stellt In gewisser Hinsicht eine Sonderform des überwachten Lernens dar. Vom überwachten Lernen unterscheidet es sich jedoch dadurch, dass keine vorgegebenen korrekten Input-Output-Paare Verwendung finden. Das Training erfolgt eher situativ und dynamisch, auf der Grundlage von „trial & error“: Ähnlich wie beim menschlichen Verstärkungslernen, wird das System dazu animiert, eigenständig eine Strategie zu entwickeln, um „Belohnungen“ zu maximieren. Dazu wird ihm nicht explizit angegeben, welche Handlung in einer spezifischen Situation die beste ist, sondern zu bestimmten Zeitpunkten werden „Belohnungen“ oder auch „Bestrafungen“ erteilt, je nachdem inwieweit der eingeschlagene Weg als „richtig“ einzuschätzen ist. Daraus leitet es näherungsweise eine Nutzenfunktion ab, auf deren Grundlage versucht wird, die kausalen Zusammenhänge zu identifizieren.
AlphaGo: eigenständige Taktik durch Belohnung
Anwendung findet dieses Lernprinzip insbesondere bei Spielen. So beruhte der berühmte Erfolg des Google-Systems AlphaGo über den Go-Großmeister Lee Sedol in erheblichem Maße darauf, dass der dahinterstehenden KI, abgesehen von den grundlegenden Regeln, keine spezifischen Spielzüge und -strategien vorab antrainiert wurden, sondern sie sich eigenständig eine eigene Taktik erstellte, die sich an einer permanent optimierten „Gewinnfunktion“ ausrichtete. Das System belohnte sich durch den Sieg gewissermaßen selbst und stellte sämtliche Aktionen in den Dienst des Zieles.
Conversion-Optimierung mit Reinforcement Learning
Im Marketing ist hier insbesondere eine autonome Conversion-Optimierung denkbar. Der Motorradbauer Harley-Davidson setzte ein derartiges System ein, mit dem Ziel, möglichst viele Termine für Probefahrten vereinbaren zu können. Eine KI kombinierte dabei verschiedene Werbemittel mit verschiedenen Social-Media-Kanälen und optimierte eigenständig diese Faktoren mit dem Ziel einer möglichst hohen Anzahl an Terminvereinbarungen, wozu sich die Interessenten registrieren mussten.
Unsupervised Learning: Musteridentifizierung
Anders als bei den zuvor genannten Lern-Methoden liegen beim unüberwachten Lernen keinerlei vorgegebenen Datenpaare oder zu erreichende Zielwerte vor, mögliche kausale Zusammenhänge sind zunächst unbekannt. Stattdessen geht es gerade darum, das Vorhandensein von Mustern und Strukturen in den Daten aufzudecken und Regeln daraus abzuleiten.
Marktsegmentierung und Clusteranalyse
Typische Anwendungsfälle liegen einerseits in der Segmentierung, andererseits in der Komprimierung. Erstere hat die Gruppierung der Daten nach Gemeinsamkeiten zur Aufgabe – wie man es von einer Marktsegmentierung oder klassischen Clusteranalyse kennt. Das System erstellt also eigenständig Kriterien zur Kategorisierung und sortiert die Daten entsprechend. Dies kommt beispielsweise bei der Aufdeckung von Anomalien, etwa auch in der frühzeitigen Krebserkennung durch die Analyse von computertomographischen Körperscans zum Einsatz. Im Bereich des Marketings ist hier die automatisierte Identifizierung spezifischer Kundengruppen zu nennen, für die dann in einem nächsten Schritt maßgeschneiderte Werbemittel erstellt oder zielgenaue Produktempfehlungen abgegeben werden können.
Komprimierung und Konzentration auf das Wesentliche
Komprimierung hat das Ziel, eine Vielzahl von Eingabewerten in einer kompakteren Form darzustellen und sich auf die Hauptkomponenten von Zusammenhängen zu konzentrieren, ohne Einbußen in der Aussagekraft hinnehmen zu müssen. Abgesehen von der Möglichkeit, auf diese Weise Rechenoperationen einfacher und damit handhabbarer zu gestalten, eröffnet dies auch Ansätze wie die Haupt-Einflussfaktoren einer bestimmten Entwicklung zu identifizieren, etwa die Aufdeckung bestimmter, besonders wesentlicher und unter Umständen nicht offensichtlicher Motive für die Kündigung von Kunden.
KI im Marketing: Synchronisierung von Zielen und maschinellen Lernmethoden
Die Einsatzmöglichkeiten von KI im Marketing werden sehr stark von der Wahl der entsprechenden maschinellen Lernmethoden geprägt. Für die Praxis bedeutet dies, dass die Zielrichtung der Maßnahmen vorab detailliert festzulegen ist, um mögliche Datenmodelle exakt daran auszurichten. Nur dann gestattet der Rückgriff auf Künstliche Intelligenz die hochgradig automatisierte systematische Erfassung von Informationen sowie deren operative Verarbeitung.
Mehr Informationen zum Thema KI im Marketing finden Sie im Buch von Andreas Wagener Künstliche Intelligenz im Marketing, Haufe, Freiburg, 2023
Weitere Informationen zum Thema „KI im Marketing“ finden Sie hier:
Vortrag/Keynote von Prof. Dr. Andreas Wagener: „Ein neues Zeitalter im Marketing: Künstliche Intelligenz, maschinelle Kreativität, virtuelle Realitäten & DNA-Targeting“:
Mehr zu Themen wie Industrie 4.0, Big Data, Künstliche Intelligenz, Digital Commerce und Digitaler Ökonomie finden Sie auf unserer Newsseite auf XING sowie auf Facebook.
Pingback: KI im Marketing: maschinelle Kreativität und virtuelle Influencer - Nerdwärts.de
Pingback: Die 3A des KI-Marketings - Nerdwärts.de
Pingback: Personalisierung in der Kundenkommunikation mittels KI - Nerdwärts.de
Pingback: KI im B2B-Marketing - Nerdwärts.de
Pingback: Evolutionäre Algorithmen: Die nächste Entwicklungsstufe der KI? - Nerdwärts.de
Pingback: Algorithmic Governance - KI und Algorithmen in der Politik - Nerdwärts.de
Pingback: Transparenz und Verantwortung: Das Legitimationsproblem algorithmischer Entscheidungen in der Politik - Nerdwärts.de
Pingback: Churn Management und Kundenrückgewinnung mit KI - Nerdwärts.de
Pingback: Live-Kommunikation im Metaverse - Nerdwärts.de
Pingback: KI im Weinbau: Anbau, Weinbereitung und Marketing - Nerdwärts.de
Pingback: Plattformregulierung durch Dateneigentum: Hürden und Ansätze - Nerdwärts.de